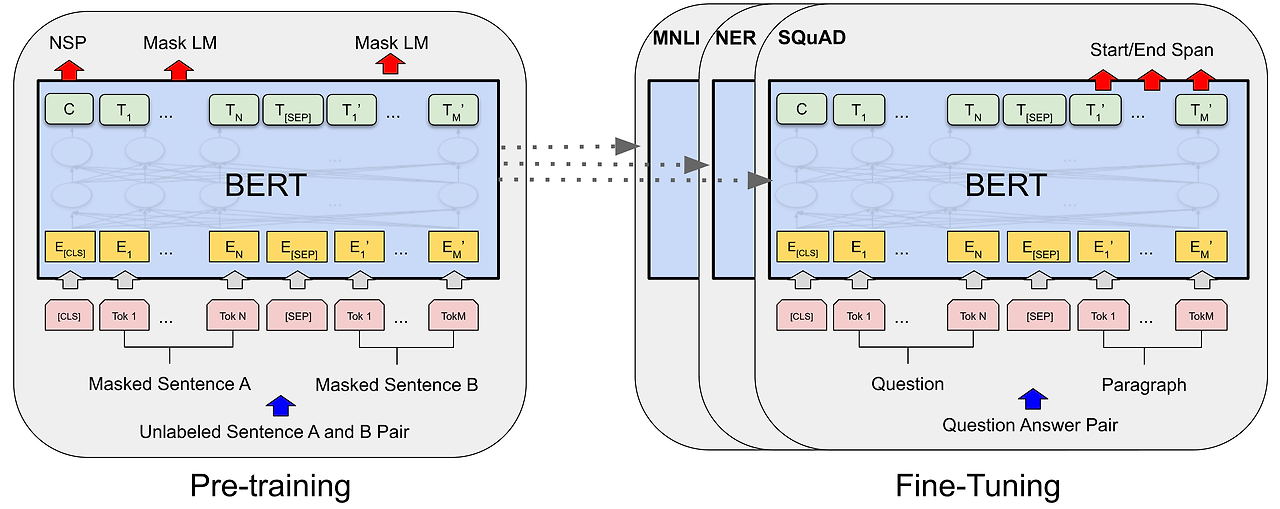
BERT는 2018년 구글이 발표한 자연어 처리(NLP)모델로,
Transformer 아키텍쳐를 기반으로 한 사전 학습 언어 모델 (Pre-trained Language Model)입니다.
NLP의 다양한 과제를 해결하기 위해 설계된 BERT는 문맥을 양방향으로 이해한다는 점에서 기존 모델과 차별화됩니다.
BERT의 등장배경
기존 RNN, LSTM기반 모델은 계산 속도가 느리고 긴 문맥을 처리하는데 제약이 있었습니다.
또한 단방향 모델(예: GPT)는 문맥을 한 방향으로만 처리하거나 제한된 방식에 국한되었습니다. 이로인해 문맥 정보 손실도 발생했었구요.
이와 더불어 Attention 메커니즘 기반의 Transformer는 병렬 연산을 지원하며 긴 문맥 처리 능력을 향상시켰으며, 이를 활용한 모델이 NLP 문제에서 더 높은 성능을 보이기 시작했습니다.
BERT의 입력과 출력
- 입력
- Tokenization : BERT 는 WordPiece 토크나이저를 사용하여 단어를 작은 단위로 분리합니다. playing -> ["play", "##ing"]
- 입력 시퀀스 구성 : 입력은 다음 세가지 유형으로 구성됩니다.
- [CLS] 토큰 : 문장의 시작을 나타내며, 문장 전체의 표현을 학습합니다.
- [SEP] 토큰 : 두 문장 사이를 구분합니다.
- 단어 토큰 : WordPiece로 분리된 토큰입니다.
- 포지션 임베딩 : 각 토큰의 위치 정보를 나타냅니다.
- 세그먼트 임베딩 : 두 문장의 구분 정보를 나타냅니다.
- (예) "Hello, how are you?" + "I am fine." => [CLS] Hello, how are you? [SEP] I am fine. [SEP]
- 출력
- 각 토큰에 대한 임베딩 벡터를 반환합니다. 이 벡터는 문맥을 포함한 단어 표현을 나타냅니다.
- 특정 NLP과제에 따라 출력의 사용 방식이 달라집니다.
- [CLS] 벡터 : 문장 분류 과제(감정 분석, 문장 간 관계 예측)
- 각 토큰 벡터 : 개체명 인식(NER), 질의 응답(QA) 과제
BERT 학습
BERT는 Wikipedia와 BooksCorpus 데이터를 사용해 아래의 두 가지 주요 과제를 통해 사전 학습 되었습니다.
- Masked Language Modeling (MLM) : 문장에서 일부 단어를 [MASK]로 가리고 이를 예측합니다. 양방향 문맥정보를 학습하게 됩니다.
- Next Sentence Prediction (NSP) : 두 문장이 연속적으로 이어지는지를 판단합니다. 첫 번째 문장 뒤에 진짜 연속문장 또는 랜덤 문장을 제공합니다.
결론
BERT는 다양한 NLP과제에서 SOTA성능을 달성하였으며, 언어 표현이 풍부하고 특정 과제를 위해 빠르고 간단한 미세 조정만 필요하며, 병렬 처리가 가능해 학습 효율이 높은 강점이 있습니다. 다만 모델이 무겁기 때문에 학습과 추론에 자원 소모가 크고 느린 추론속도로 실시간 애플리케이션 사용시 제한적입니다.
BERT 는 NLP 발전의 큰 전환점을 제공하며, 이후 출시된 많은 모델 (GPT, RoBERTa, ALBERT 등)의 기초가 되었습니다.
'Data Science > Algorithm' 카테고리의 다른 글
| DIN (Deep Interest Network) (0) | 2024.11.27 |
|---|---|
| Optimizer (0) | 2024.11.26 |
| RoBERTa - A Robustly Optimized BERT Pretraining Approach (1) | 2024.11.23 |
| LoRA (Low-Rank Adaptation) (0) | 2024.11.22 |
| Sentence Transformer (0) | 2024.11.21 |



댓글