
LoRA(Low-Rank Adaptation)는 대규모 언어 모델(LLM)의 효율적인 파인튜닝을 위한 기법입니다.
Low-Rank : 저순위 라는 개념은 주로 수학, 선형대수학, 그리고 머신러닝에서 행렬이나 텐서의 성질과 관련이 있습니다.
구체적으로 말하면, Low-Rank는 행렬의 계수(rank)가 낮다는 것을 의미합니다.
이를 이해하려면 Rank(계수)개념부터 알아야 합니다.
Rank(계수) 란?
행렬의 Rank는 행렬에서 독립적인 행 또는 열 벡터의 최대 수를 나타냅니다.
예를 들어 3x3행렬이 있을때 그 행렬의 Rank는 최대 3입니다.
이때 Full-Rank (완전계수)는 Rank가 행렬의 최대크기와 같을 때를 나타내고,
Low-Rank (저계수)는 Rank 가 행렬의 최대 크기보다 작을 때를 나타냅니다.
그래서 Low-Rank행렬은 독립적인 정보가 상대적으로 적은 행렬을 의미합니다.
즉 행렬의 대부분의 정보가 많은 중복 정보를 포함하고 있으며 특정 패턴이나 구조로 압축될 수 있다는 의미입니다.
LoRA의 핵심 아이디어
LoRA는 모델의 거대한 가중치 행렬이 실제로는 Low-Rank 구조를 가진다고 가정합니다.
즉, 모델의 파라미터는 많은 중복된 정보를 가지고 있고, 이를 더 작은 Low-Rank행렬로 근사할 수 있다는 것이죠.
그래서 LoRA는 다음과 같이 동작합니다.
LoRA 동작방식
- 원래 가중치 행렬을 고정 (freeze) : 모델의 사전 학습된 모델의 가중치를 수정하지 않습니다.
- Low-Rank 행렬 추가 : 각 계층의 가중치 행렬에 Low-Rank 행렬을 추가하여 학습합니다. 이 Low-Rank 행렬은 새로운 작업에 필요한 정보만 학습합니다.
- 전체 파라미터를 줄임 : 추가된 Low-Rank 행렬만 학습하기 때문에 계산량이 크게 줄어듭니다.
LoRA는 다음과 같이 표현할 수 있습니다.
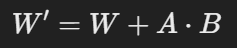
- W : 사전 학습된 원래의 가중치 행렬
- A : 작은 크기의 Low-Rank 행렬 (학습 가능)
- B : 또 다른 작은 크기의 Low-Rank 행렬 (학습 가능)
즉 A와 B만 학습하기 때문에 학습해야 할 파라미터 수가 크게 줄어듭니다.
LoRA 적용 사례
최근 연구에 따르면, LoRA를 활용한 파인튜닝 모델이 GPT-4를 능가하는 성능을 보였습니다.
특히, 4비트 LoRA로 파인튜닝된 모델은 기본 모델보다 평균 34점, GPT-4보다 10점 높은 성능을 기록했습니다.
'Data Science > Algorithm' 카테고리의 다른 글
| BERT - Bidirectional Encoder Representation from Transformers (0) | 2024.11.24 |
|---|---|
| RoBERTa - A Robustly Optimized BERT Pretraining Approach (1) | 2024.11.23 |
| Sentence Transformer (0) | 2024.11.21 |
| Sparse Attention (0) | 2024.11.19 |
| 특이값 분해 (Singular Value Decomposition, SVD) (1) | 2024.11.18 |



댓글