Contextual Bandit은 주로 추천 시스템, 광고 배치, A/B 테스트와 같은 문제에서 사용되는
강화 학습 (또는 온라인 학습) 알고리즘으로
시스템은 사용자 또는 상황에 맞는 최적의 활동을 선택할 수 있습니다.
Contextual Bandit
이전 글(링크)에서 설명드렸던 MAB에서 파생된 개념입니다.
다중 슬롯머신 문제는 여러 슬롯머신 중 하나를 선택해 최적의 보상을 얻는 것을 목표로 하는 문제입니다.
하지만 Contextual Bandit에서는 선택할 때 상황에 대한 정보가 추가됩니다.
예를 들어 날씨가 더운 날에는 아이스크림 가게가 인기가 있고, 추운 날에는 핫초고 가계가 인기 있을 수 있는 것처럼요.
Agent는 주어진 컨텍스트를 통해 각각의 행동을 선택하며,
각 행동은 보상(Reward)을 가지고, Agent는 최적의 보상을 얻기 위해 반복적으로 선택합니다.
구성요소
- 상황 (Context) : 선택 시점의 상황정보 (사용자 나이, 성별, 기후, 시간 등)
- 행동(Arm) : 선택 가능한 옵션 또는 행동
- 보상 (Reward) : 선택한 행동으로부터 얻는 보상
LinUCB 알고리즘이란?
LinUCB는 Contextual Bandit 문제를 해결하기 위한 대표적인 알고리즘 중 하나입니다.
각 행동의 기대 보상을 선형 모델(Lin: Linear)로 예측하고,
해당 행동을 선택할 때 상한 신뢰 구간(UCB: Upper Confident Bound)을 고려하여
exploration-exploitation 균형을 맞춥니다.
LinUCB알고리즘은 각 행동(Arm)에 대해 다음과 같은 선형 회귀 모델을 사용하여 보상을 예측합니다.
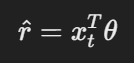
- r_hat : 행동의 예측 보상
- x_t : 현재 컨텍스트 (특징 벡터)
- θ : 모델 파라미터
Upper Confidence Bound
LinUCB는 높은 보상을 얻을 가능성이 있는 행동을 선택하되,
불확실성이 높은 행동도 선택하여 정보 탐색을 시도합니다.
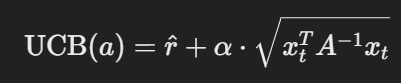
- α : 탐색 정도 조절 하이퍼 파라미터
- A : 파라미터 θ의 불확실성을 나타내는 행렬
- A^-1 : A의 역행렬 (불확실성 정도)
- root : 예측 보상의 불확실성, 즉 보상의 신뢰구간 폭
LinUCB 절차
- 초기화 : 각 행동 a에 대해 A ← I (단위행렬), b ← 0 백터로 초기화
- 예측 : 각 행동 a 에 대해 A^-1을 계산하고, 파라미터 θ = A^-1 * b로 추정하고 r_hat을 계산하여 각 행동의 보상을 예측
- 선택 : 각 행동에 대해 UCB점수를 계산하여 가장 높은 값을 가진 행동을 선택
- 업데이트 : 선택한 행동 a에 대한 보상 r을 계산
- A ← A + x_t * x_t
- b ← b + r * x_t
LinUCB 알고리즘의 장점은 무엇일까요?
- 상황을 고려한 선택: 이 알고리즘은 단순히 과거 데이터의 평균을 참고하는 것이 아니라, 현재 상황을 반영하여 보다 나은 결정을 내릴 수 있습니다.
- 탐험과 활용의 균형: UCB의 개념을 적용해, 아직 충분히 알려지지 않은 선택지에 대해서도 탐색할 수 있습니다.
- 학습 능력: 모델을 지속적으로 업데이트하며 점차 더 정확한 예측을 할 수 있게 됩니다.
'Data Science > Algorithm' 카테고리의 다른 글
| RAG (Retrieval-Augmented Generation) (1) | 2024.11.16 |
|---|---|
| 최소 자승법 (Least Squares Method) (0) | 2024.11.15 |
| Multi-Armed Bandit (MAB) (4) | 2024.11.13 |
| Deep Cross Network (0) | 2024.11.11 |
| Hash table (0) | 2009.04.14 |



댓글