Contrastive Learning 은 컴퓨터가 데이터를 분류하거나 특성을 학습할 때
서로 다른 데이터를 구별하면서 특징을 학습하는 기법입니다.
주로 비지도 학습에 많이 활용되며, 특히 이미지나 텍스트 같은 고차원데이터에서
데이터의 특성을 잘 표현할 수 있는 임베딩을 학습하는 데 사용됩니다.
이 기법은 최근 자율학습분야에서 많이 주목받고 있으며,
라벨데이터가 적은 도메인에서 활용해도 강력한 성능을 발휘하고 있습니다.
개념
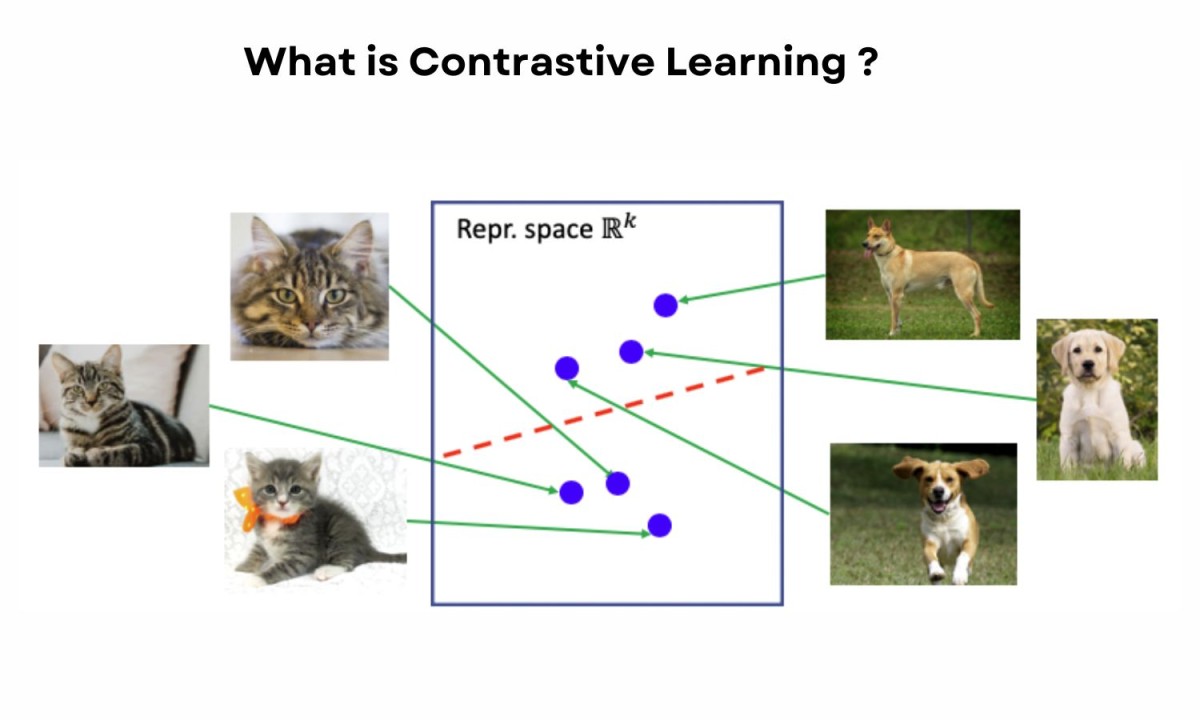
Contrastive Learning의 기본 개념은 비슷한 데이터를 가까이, 다른 데이터를 멀리 위치시키는 것입니다.
예를 들어, 두 장의 이미지가 같은 물체(예: 고양이)를 담고 있다면 이 둘의 특성을 같은 방향으로 학습하고,
서로 다른 물체(예: 고양이와 강아지)를 담고 있다면, 이 둘은 서로 멀어지도록 학습하는 방식입니다.
이렇게 하면 모델이 물체의 특징을 좀 더 정확하게 구분할 수 있게 됩니다.
이를 수행하기 위해 데이터 쌍을 사용하여 positive pair와 negative pair를 만듭니다.
positive pair는 서로 비슷하거나 동일한 범주의 데이터를, negative pair는 다른 범주의 데이터를 가리킵니다.
모델은 positive pair는 가까이, negative pair는 멀리 두도록 학습합니다.
텍스트에서도 비슷한 방식으로 사용할 수 있습니다.
예를 들어 문장 A와 문장 B가 같은 주제를 다룬다면 positive pair로, 문장 A와 전혀 다른 주제를 다룬 문장 C는 negative pair로 두어 모델이 서로 다른 주제를 학습하도록 할 수 있습니다.
Contrastive Learning의 특징
- 비지도 학습의 효율성 : 라벨이 없는 대규모 데이터를 사용할 수 있어 많은 양의 데이터로 학습이 가능합니다.
- 일반화 성능 : 데이터 간 관계에 따라 특성을 학습하므로 일반화 성능이 좋으며, 새로운 데이터에도 잘 대응할 수 있습니다.
- 다양한 응용 가능성 : 이미지, 텍스트, 음성 데이터 등 다양한 종류의 고차원 데이터를 학습할 수 있습니다.
- 강력한 특성 추출 : 비슷한 데이터를 가깝게, 다른 데이터를 멀게 학습함으로써 데이터의 핵심적인 특징을 효율적으로 학습합니다.
- negative pair 선정이 성능에 큰 영향을 줌 :어떻게 negative pair를 선정하느냐에 따라 모델 성능이 크게 달라질 수 있어 신중한 설계가 필요합니다.
Contrastive Learning과 비슷한 기법들
- Siamese Network : Siamese Network는 두 개의 동일한 신경망을 통해 두 입력 간의 유사도를 학습하는 기법입니다. 얼굴 인식이나 서명 인식 등에서 두 데이터의 유사도를 판단할 때 많이 사용됩니다. Contrastive Learning과 구조는 비슷하지만, 주로 특정한 유사도 계산에 특화된 경우가 많습니다.
- Triplet Loss : Triplet Loss는 하나의 앵커 데이터와 그와 비슷한 양성 데이터, 그리고 다른 음성 데이터를 사용하여 모델을 학습합니다. 앵커와 양성은 가까이, 앵커와 음성은 멀리 떨어지도록 모델을 학습하는 방식입니다. 주로 이미지 검색, 추천 시스템 등에 사용됩니다. Triplet Loss는 한 번에 세 개의 데이터를 활용하여 유사도를 계산하므로, 좀 더 정밀하게 학습할 수 있습니다.
'Data Science' 카테고리의 다른 글
| Transfer Learning (1) | 2024.11.20 |
|---|---|
| 아이겐벡터 (Eigenvector) (2) | 2024.11.17 |
| 트랜스포머 (Transformer) 모델 (1) | 2024.11.09 |
| 딥러닝 처음 접할 때 어려워하는 몇가지 핵심 개념들 (0) | 2024.11.08 |
| Activation Functions (0) | 2024.11.07 |



댓글